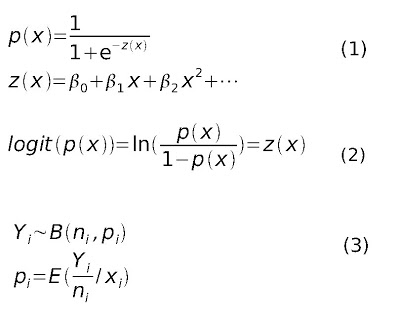La serie temporal adquirida desde un experimento es frecuentemente filtrada. En algunos casos, el filtrado los realiza el mismo adquisidor de datos, en otros el mismo experimentador realiza el filtrado por medio de programas dedicados. En cualquier caso se debe tener cuidado al filtrar la serie temporal, pues el filtrado puede modificar la dinámica que a uno le interesa hallar. Sea la serie temporal de datos {x_i} con i=1 a N tan grande como se requiera, luego un filtro FIR «Finite Impulse Response», se lo puede modelar con la ecuación (1), donde el coeficiente es menor que la unidad. La razón de este nombre se debe a la respuesta del filtro a la señal impulsiva x_i={1, 0, 0, …} que estará compuesta por una secuencia finita de términos z_i no nulos. En el caso de tender L a infinito se obtiene un IIR «Infinte Impulse Response», se lo puede modelar con la ecuación (2), donde el coeficiente es menor que la unidad. Esta es una versión discreta de un filtro RC pasa bajos. Badii y Politi en 1986 mostraron que el filtrado IIR cambia la dimensión de correlación observada de un atractor, cosa no deseable, en cambio para el filtro FIR existe un teorema matemático que muestra que este filtrado no modifica la dimensión de correlación del atractor observado, siempre y cuando el espacio de reconstrucción o de «embeding» tenga dimensión mayor a la dimensión de correlación del atractor. El promedio acumulado (3) es un caso particular de una generalización de un filtro FIR lineal. Es de gran utilidad en series temporales para eliminar ruidos numéricos o de rendondeo, pero no es efectivo cunado se quiere eliminar ruido de datos. Por otro lado los filtros IIR son de utilidad para crear filtros paso de banda numéricos en series temporales donde no interesa el comportamiento caótico del sistema. La mayor generalización de un filtro FIR es la SVD «Singular Value Decomposition» donde el valor de los coeficientes del polinómio de filtrado se los escoge de forma tal de minimizar la varianza de datos.
H.J. Ansoff, en su libro Corporate Strategy (1965), dedica todo un capítulo al problema de la sinergia, tratándola como uno de los factores que deben ser tomados en cuanta para un método de decisión estratégica y la describe como una medida de los efectos unidos, identificándola con el efecto:2 + 2 = 5. Con la ayuda de símbolos matemáticos simples, Ansoff busca el significado, desde el punto de vista de administración, del concepto de sinergia. Algunas acertividades básicas son:
Se dice que existe sinergia cuando la suma de las partes es diferente del todo.
Un objeto posee sinergia cuando el examen de una o alguna de sus partes (incluso a cada una de sus partes) en forma aislada, no puede explicar o predecir la conducta del todo.
En general, a la totalidades desprovistas de sinergia se conoce como conglomerados. Los conglomerados es un conjunto de objetos de los cuales abstraemos ciertas características, eliminamos aquellos factores ajenos al estudio y luego observamos el comportamineto de las variables que nos interesan, en donde las posibles relaciones que entre ellos se desarrollan no afectan la conducta de cada una de las partes y es la base del reducionismo. Al conocer que existen objetos que tienen sinergia, es factible eliminar como herremienta de análisis el sistema reduccionista como método de estudio y usar la Teoría General de Sistemas. Terminología atribuída al biólogo austriaco Ludwig von Bertalanffy, quien acuñó la denominación a mediados del siglo XX.
Se puede decir que la palabra sinergia proviene del griego y su traducción literal sería cooperación; no obstante (según la Real Academia Española) se refiere a la acción de dos (o más) causas cuyo efecto es superior a la suma de los efectos individuales.
La distancia de Levenshtein es un algoritmo tal que dadas dos cadenas, devuelve un entero que da una idea de la distancia (o parecido) entre ellas. Este entero se calcula contando las transformaciones que es necesario hacer sobre una de estas cadenas para obtener la otra. Estas posibles tranformaciones son:
Borrado de un carácter.
Inserción de un carácter.
Substitución de un carácter por otro.
Por ejemplo, la distancia entre «HOLA» y «TROLA» es 2, ya que hay que hacer 2 operaciones sobre la palabra «HOLA» para obtener «TROLA»: substituir la H por una R e insertar una T. Cuanto más corta es la distancia entre las dos cadenas, más parecidas son. Si la distancia es 0, las dos palabras son iguales. Es útil en programas que determinan cuán similares son dos cadenas de caracteres, como es el caso de los correctores de ortografía. Se le considera una generalización de la distancia de Hamming, que se usa para cadenas de la misma longitud y que solo considera como operación la substitución.
En estadísticas, regresión logística es un modelo utilizado para la predicción de probabilidad de ocurrencia de un evento con el uso de variables aleatorias divididas en categorías. Por ejemplo, la probabilidad de que una persona tenga un ataque al corazón en un determinado período de tiempo puede ser predicho a partir del conocimiento de la edad, del sexo y el índice de masa corporal. El análisis de regresión logística se utiliza ampliamente en medicina, las ciencias sociales, y en aplicaciones de marketing. La regresión logística es una clase de modelo conocido como modelo lineal generalizado. La expresión matemática de la distribución de probabilidades logística (ddpl)es dada en (1) donde la «entrada» es x y la «salida» es p(z). La ddpl puede tomar como un aporte cualquier valor infinito negativo a positivo infinito como entrada, mientras que la salida se limita a valores entre 0 y 1. La función z(x) representa la exposición a algún conjunto de factores de riesgo, mientras que p(z) representa la probabilidad de que ocurra un resultado particular, habida cuenta de ese conjunto de factores de riesgo dados. La función z(x) es una medida de la contribución total de todos los factores de riesgo utilizados en el modelo y es conocida como el logit(x) ver (2) donde los coeficientes pueden ser estimados por regresión polinómica. También se conoce a logit(x) como odd(x) muy usado en meta-análisis. La regresión logística analiza datos distribuidos binomialmente de la forma (3) donde los números de ensayos Bernoulli n_i son conocidos y las probabilidades de éxito p_i son desconocidas. Entonces obtenido en base a lo que cada ensayo (valor de i) y el conjunto de variables explicativas/independientes pueda informar acerca de la probabilidad final. Estas variables explicativas pueden pensarse como un vector X_i k-dimensional de manera que la probabilidad buscada es la expresión condicional indicada en (3).
La matriz de Leslie es un modelo discreto y edad-estructurado de crecimiento poblacional muy popular en la ecología. Fue inventada por P.H. Leslie. Las matrices de Leslie (también conocido como Modelo de Leslie) es una de las mejores conocidas maneras para describir el crecimiento poblacional y su distribución por edades proyectada, donde sólo es tenido en cuenta el sexo femenino. La matriz de Leslie se utiliza para modelar los cambios en una población de organismos en un período de tiempo. En un modelo Leslie, la población se divide en grupos, ya sea basado en clases de edad o etapa de la vida. En cada paso del tiempo la población está representada por un vector con un elemento para cada clase de edades donde cada elemento indica el número de individuos presentes en dicha categoría. La matriz de Leslie (L)es una matriz cuadrada en cambio la población tiene elementos vectoriales (N). El (i, j) ª elemento en la matriz indica el número de individuos estan en la clase de edad i en el próximo paso del tiempo para cada individuo en la etapa actual j. En cada paso del tiempo, la población de vectores se multiplica por la matriz de Leslie para generar la población de vectores para la siguiente generación temporal. Esto puede ser escrito como; N(t+1)=L N(t); dónde N(t) es la población vectorial en el tiempo t y L es la matriz de Leslie. El modelo de Leslie es muy similar a un tiempo discreto la cadena de Markov. La principal diferencia es que en un modelo de Markov, uno tendría f_x + s_x = 1 para cada x, mientras que el modelo Leslie pueden ser estas sumas mayor o menor que uno.
Para construir una matriz de Leslie, alguna información debe ser conocida, esta es:
n_x, el número de individuos en cada clase de edad x.
s_x, la fracción de individuos que sobrevive dede la x a la edad x +1.
f _x, la fecundidad, el per cápita promedio de las hembras descendientes de n_1 nacidas de las madres de edad x.
La piedra en el zapato de la física Argentina. "Nullius addictus iurare in verba magistri"

 La serie temporal adquirida desde un experimento es frecuentemente filtrada. En algunos casos, el filtrado los realiza el mismo adquisidor de datos, en otros el mismo experimentador realiza el filtrado por medio de programas dedicados. En cualquier caso se debe tener cuidado al filtrar la serie temporal, pues el filtrado puede modificar la dinámica que a uno le interesa hallar.
La serie temporal adquirida desde un experimento es frecuentemente filtrada. En algunos casos, el filtrado los realiza el mismo adquisidor de datos, en otros el mismo experimentador realiza el filtrado por medio de programas dedicados. En cualquier caso se debe tener cuidado al filtrar la serie temporal, pues el filtrado puede modificar la dinámica que a uno le interesa hallar.