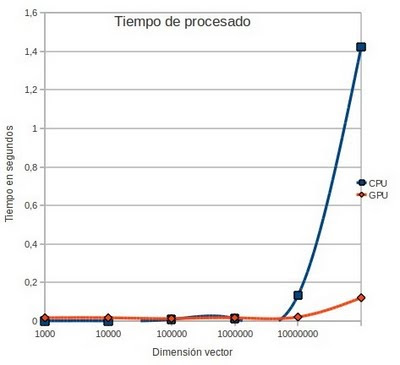

En este grafo muestro los tiempos de procesamiento en función de la dimensión de vectores en el siguiente núcleo de cálculo:
__global__ void dotProdKernel(float *_dst, const float* _a1, const
float* _a2, int _dim) {
const unsigned int outputIdx = blockIdx.x * MAX_THREADS + threadIdx.x;
float reg = 0.f;
for(unsigned int inputIdx = outputIdx; inputIdx < _dim; inputIdx += MAX_BLOCKS * MAX_THREADS)
{
reg += _a1[inputIdx] * _a2[inputIdx];
}
_dst[outputIdx] = reg;
}
el cuál corresponde a un producto escalar entre vectores. Como se puede apreciar para dimensiones mayores a los 10 millones de componentes la GPU tiene una mejora del orden del 1000% en el tiempo de cálculo para una arquitectura Tesla.
CPU: Intel(R) Core(TM) i7 CPU 950 @ 3.07GHz
GPU: nVidia Corporation GF100 [Tesla C2050 / C2070]