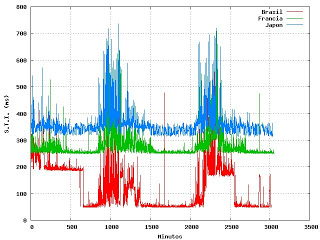

Bueno, creo que cada vez que experimento más descubro cosas nuevas, por lo menos para mi. He finalizado las mediciones de los S.T.I. (Sparseness Time Interval) en los pingueos hacia Yahoo, Brasil, Francia y Japón. Como se ve en la figura en todos aparecen unos burst cada 20 horas en promedio y su duración es de 5 horas promedio. Pero además en el caso de Brasil ocurre un comportamiento de onda lenta que tiende a no hacer constante el mínimo en los S.T.I., cosa que no ocurre con los otros casos. Los motivos los desconozco.
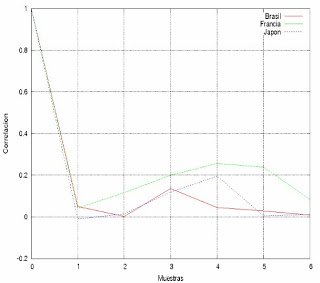
Two-time correlation function en pruebas de «pingueo».

Como he mencionado en un post anterior, estoy estudiando la dinámica de la red de redes (Internet) efectuando testeos de ping respecto a 3 sitios definidos. En mi caso yahoo Brasil, Francia y Japón. En este caso me puse a medir la two-time correlation function (TTCF). La cual se la define como (formula escrita en LaTex):
C_t(t_1,t_2)=frac{E(x_1*x_2)-E(x_1)*E(x_2)}{sigma_1*sigma_2}
Donde x_1 y x_2 son dos subseries temporales disyuntas de longitud fija de la misma serie temporal. sigma es la varianza de cada subserie, E(.) es la esperanza estadística y t_1 menor que t_2. Pero de manera tal que no se solapen las muestras. En la figura se muestra esas mediciones para cada sitio en función de las muestras realizadas sobre subseries de 1700 valores cada una en diferentes fechas. En la siguiente tabla se da los resultados numéricos hallados.
Fecha | Brasil | Francia | Japón
2007/05/18 | 1.000000e-00 | 1.000000e-00 | 1.000000e+00
2007/06/19 | 5.018778e-02 | 4.243639e-02 | -9.786052e-03
2007/06/26 | 2.414457e-03 | 1.168911e-01 | 1.491142e-02
2007/07/05 | 1.365180e-01 | 2.005155e-01 | 1.192697e-01
2007/07/13 | 4.488001e-02 | 2.563852e-01 | 1.958555e-01
2007/07/21 | 2.917548e-02 | 2.390630e-01 | 5.458251e-03
2007/07/26 | 8.516783e-03 | 8.358991e-02 | 1.145037e-02
Lo difícil de verificar es la condición siguiente (dada la poca cantidad de puntos que tengo)
C_t(t_1,t_2)=C(t_2-t1)
donde C(.) es la función de auto correlación de la serie temporal. Pues si se verifica esta condición en sistema es Ergódico y además tiene la propiedad de Invariancia Traslacional de Tiempos o Time Translation Invariance en inglés. Esto permite garantizar que la serie temporal en cuestión tiene una medida invariante de probabilidad, cosa que supuse en un momento pero ahora lo estoy dudando.

Que es un sistema complejo?

Un sistema complejo es un sistema compuesto por varias partes interconectadas o entrelazadas cuyos vínculos contienen información adicional y oculta al observador. Como resultado de las interacciones entre elementos, surgen propiedades nuevas que no pueden explicarse a partir de las propiedades de los elementos aislados. Dichas propiedades se denominan propiedades emergentes.
El sistema complicado, en contraposición, también está formado por varias partes pero los enlaces entre éstas no añaden información adicional. Nos basta con saber como funciona cada una de ellas para entender el sistema. En un sistema complejo, en cambio, existen variables ocultas cuyo desconocimiento nos impide analizar el sistema con precisión. Así pues, un sistema complejo, posee más información que la que da cada parte independientemente. Para describir un sistema complejo hace falta no solo conocer el funcionamiento de las partes sino conocer como se relacionan entre sí.Que características tiene un sistema complejo:
- El todo es más que la suma de las partes: esta es la llamada concepción holística. Como ya se ha dicho, la información contenida en el sistema en conjunto es superior a la suma de la información de cada parte analizada individualmente.
- Comportamiento difícilmente predecible: Debido a la enorme complejidad de estos sistemas la propiedad fundamental que los caracteriza es que poseen un comportamiento impredecible. Sólo somos capaces de prever su evolución futura hasta ciertos límites, siempre suponiendo un margen de error muy creciente con el tiempo. Para realizar predicciones más o menos precisas de un sistema complejo frecuentemente se han de usar métodos matemáticos como la estadística, la probabilidad o las aproximaciones numéricas como los números aleatorios.
- Son sistemas fuera del equilibrio: ello implica que tal sistema no puede automantenerse si no recibe un aporte constante de energía.
- Autoorganización: Todo sistema complejo emerge a partir de sus partes y fluctua hasta quedar fuertemente estabilizado en un atractor. Esto lo logra con la aparición de toda una serie de retroalimentaciones (o realimentaciones) positivas y negativas que atenúan cualquier modificación provocada por un accidente externo. Se puede afirmar que el sistema reacciona ante agresiones externas que pretendan modificar su estructura. Tal capacidad sólo es posible mantenerla sin ayuda externa mediante un aporte constante de energía.
- Las interrelaciones están regidas por ecuaciones no-lineales: estas no dan como resultado vectores ni pueden superponerse unas con otras. Normalmente todas ellas pueden expresarse como una superposición de muchas ecuaciones lineales. Pero ahí reside justamente el problema. Solo se pueden tratar de forma aproximada cosa que lleva a la imposibilidad de predicción antes citada. Por otra parte tales ecuaciones suelen tener una fuerte dependencia con las condiciones iniciales del sistema lo que hace aún más difícil, si cabe, evaluar su comportamiento.
- Es un sistema abierto y disipativo: energía y materia fluyen a través suyo. Pues justamente un sistema complejo, en gran medida se puede considerar como una máquina de generar orden para lo cual necesita del aporte energético constante que ya hemos comentado.
- Es un sistema adaptativo: como ya se ha dicho antes el sistema autoorganizado es capaz de reaccionar a estímulos externos respondiendo así ante cualquier situación que amenace su estabilidad como sistema. Experimenta así, fluctuaciones. Esto tiene un límite, naturalmente. Se dice que el sistema se acomoda en un estado y que cuando es apartado de él tiende a hacer todos los esfuerzos posibles para regresar a la situación acomodada. Esto ocurre por ejemplo con el cuerpo humano que lucha constantemente para mantener una misma temperatura corporal, o las estrellas cuya estructura se acomoda para mantener siempre una luminosidad casi constante.
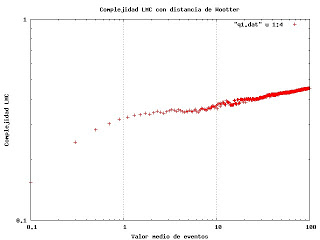
Medir la complejidad LMC en un proceso de Poisson.

Antes de comentar mis resultados, comento que es la complejidad. Desde el punto de vista de su medición, no lo que es un sistema complejo que lo haré en otro post.
La complejidad se define como la cantidad de información necesaria para describir un sistema. Así, cuanto más complejo es un sistema más información hay contenida en él. A su vez, un sistema complejo que contenga mucha información será altamente no-entrópico u ordenado. Cuanto más orden, más información para establecer dicho orden. El orden no son más que enlaces, interrelaciones entre las diferentes partes del sistema siguiendo algún tipo de jerarquía y estructura definidas. O, dicho de otra forma, información no es sólo cómo hacer las células de nuestro cuerpo, sino también las relaciones e interacciones que mantendrán entre ellas (o cualquier otra unidad que se considere, p.ej. proteínas o genes). Y eso es mucho más de lo que podemos ver a simple vista. Pero hace falta un buen criterio que se pueda usar para comparar y juzgar cuan complejo es un sistema respecto al otro. Para la complejidad de los sistemas no vivos, moléculas, macro moléculas y estructuras macro moleculares, basta con hacer uso de los criterios para medir la entropía en la química.
Pero para sistemas complejos no basta con esta definición y se debe apelar al uso de una extensión de la definición de la entropía conocida como entropía de Shannon o de entropía de la información. El concepto básico de entropía en Teoría de la Información tiene mucho que ver con la incertidumbre que existe en cualquier experimento o señal aleatoria. Es también la cantidad de «Ruido» o «desorden» que contiene o libera un sistema. De esta forma, podremos hablar de la cantidad de información que lleva una señal.
Pero para medir la complejidad no basta con esta extensión. En 1995, Lopez-Ruiz, Mancini y Calbet, proponen una definición de la complejidad basada en la medida de la información pero introduciendo el concepto de desequilibrio. (ver: http://prola.aps.org/abstract/PRE/v63/i6/e066116 Tendency towards maximum complexity in a nonequilibrium isolated system) Ellos proponen que la complejidad de un sistema ordenado es la misma que la de un sistema desordenado, en cambio un sistema caótico con comportamiento emergente debe tener una complejidad mayor que los anteriores.
Para medir la complejidad de una variable aleatoria con distribución de Poisson, uso como medida de desequilibrio la distancia de Wootter (ver: http://prola.aps.org/abstract/PRD/v23/i2/p357_1 Statistical distance and Hilbert space). Como se puede apreciar la variable de control es el número medio de eventos positivos. Esta crece hasta una meseta, a partir de la cual se incrementa linealmente en el gráfico log-log. Este cambio de comportamiento es debido a que la distribución de Poisson se comporta como una Gausiana para valores medios de eventos positivos grandes. Teoría formal sobres este comportamiento no existe por ahora, pero muestra que la complejidad de los procesos de Poisson es menor a la de los procesos Gausianos.
La complejidad se define como la cantidad de información necesaria para describir un sistema. Así, cuanto más complejo es un sistema más información hay contenida en él. A su vez, un sistema complejo que contenga mucha información será altamente no-entrópico u ordenado. Cuanto más orden, más información para establecer dicho orden. El orden no son más que enlaces, interrelaciones entre las diferentes partes del sistema siguiendo algún tipo de jerarquía y estructura definidas. O, dicho de otra forma, información no es sólo cómo hacer las células de nuestro cuerpo, sino también las relaciones e interacciones que mantendrán entre ellas (o cualquier otra unidad que se considere, p.ej. proteínas o genes). Y eso es mucho más de lo que podemos ver a simple vista. Pero hace falta un buen criterio que se pueda usar para comparar y juzgar cuan complejo es un sistema respecto al otro. Para la complejidad de los sistemas no vivos, moléculas, macro moléculas y estructuras macro moleculares, basta con hacer uso de los criterios para medir la entropía en la química.
Pero para sistemas complejos no basta con esta definición y se debe apelar al uso de una extensión de la definición de la entropía conocida como entropía de Shannon o de entropía de la información. El concepto básico de entropía en Teoría de la Información tiene mucho que ver con la incertidumbre que existe en cualquier experimento o señal aleatoria. Es también la cantidad de «Ruido» o «desorden» que contiene o libera un sistema. De esta forma, podremos hablar de la cantidad de información que lleva una señal.
Pero para medir la complejidad no basta con esta extensión. En 1995, Lopez-Ruiz, Mancini y Calbet, proponen una definición de la complejidad basada en la medida de la información pero introduciendo el concepto de desequilibrio. (ver: http://prola.aps.org/abstract/PRE/v63/i6/e066116 Tendency towards maximum complexity in a nonequilibrium isolated system) Ellos proponen que la complejidad de un sistema ordenado es la misma que la de un sistema desordenado, en cambio un sistema caótico con comportamiento emergente debe tener una complejidad mayor que los anteriores.
Para medir la complejidad de una variable aleatoria con distribución de Poisson, uso como medida de desequilibrio la distancia de Wootter (ver: http://prola.aps.org/abstract/PRD/v23/i2/p357_1 Statistical distance and Hilbert space). Como se puede apreciar la variable de control es el número medio de eventos positivos. Esta crece hasta una meseta, a partir de la cual se incrementa linealmente en el gráfico log-log. Este cambio de comportamiento es debido a que la distribución de Poisson se comporta como una Gausiana para valores medios de eventos positivos grandes. Teoría formal sobres este comportamiento no existe por ahora, pero muestra que la complejidad de los procesos de Poisson es menor a la de los procesos Gausianos.
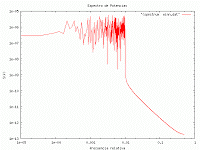
Ruido blanco limitado en banda.

Si bien el ruido blanco limitado en banda, es decir que tiene un espectro de potencias casi plano en un ancho de frecuencias, no es un proceso de Wiener. Pues este debe tener un espectro plano para cualquier valor de la frecuencia, lo que garantiza que su función de correlación sea una delta de Dirac en cero. Es muy útil a veces contar con un algoritmo que genere un ruido casi blanco ó limitado en frecuencias. Con el siguiente algoritmo obtengo tal cosa para ensayos en representaciones recursivas.
algoritmo blanco
// Algunos valores iniciales
NDATO

Que es el Leguaje Klingon?

Nota:
El lenguaje Klingon, es un lenguaje artificiál con propiedad intelectual de la Paramount Studios. Si bien esto está repreoducido sin su consetimiento, la popularida del leguaje permite un uso libre para usos didácticos.
Los klingon (tlhIngan en su idioma), son una raza de humanoides del universo Star Trek (Viaje a las Estrellas). Fueron los enemigos principales en la serie original y terminaron por convertirse en aliados de la Federación, tras el incidente en su luna Praxis, tal como se puede ver en Star Trek VI Aquel Pais Desconocido. Aparecen por primera vez en el episodio «Errand of Mercy». Reciben su nombre del Teniente Wilbur Clingan, quien sirvió junto a Gene Roddenberry en el departamento de Policía de Los Ángeles.
Con la llegada de La Nueva Generación, y demás secuelas, los klingon se convirtieron en poderosos aliados, y los rasgos de su cultura fueron encaminados hacia un parecido con los Samurai japoneses (o al menos, la concepción que en Occidente se tenía de ellos), y su aspecto fisico sufrió modificaciones con respecto a la serie original, al contar con nuevos medios técnicos y técnicas de maquillaje. Su cultura gira en torno al honor y el combate. Su sociedad está regida por un emperador que en realidad no posee gran poder, la mayor parte de éste reside en la alta artistocracia.
El idioma klingon (tlhIngan Hol, pronunciado fonéticamente como /t͡ɬɪˈŋɑn xol/) es una lengua construida y artística, creada por Marc Okrand para los estudios Paramount Pictures, como idioma vernáculo de la raza klingon en el universo de Star Trek.
Este idioma fue diseñado con un orden de palabras tipo Objeto Verbo Sujeto (OVS) para hacerlo menos intuitivo y darle un aspecto más alienígena. Se suele decir del idioma klingon que es similar a los lenguajes nativos norteamericanos en varios aspectos.para poder ver sobre su gramática ver este enlace:http://ar.geocities.com/horacio9573/klingon.html
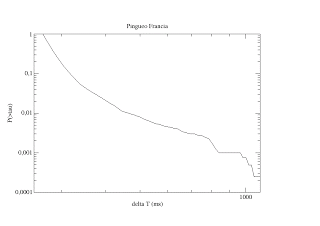
Pingueo a Francia. Un contra ejemplo a la q-exponencial?

Motivado por el trabajo publicado por Sumiyoshi Abe et al. titulado Interaction of the internet over nonequilibrium stationary stat in Tsallis statitics, aparecido en Phy. Rev. E, 67 016106 (2003). Me dediqué a repetir los experimentos para ver si obtenía una q-exponencial en la distribución cumulativa (cdf en inglés). Para ello construí el siguiente script bash para tomar a cada intervalo de un minuto una prueba ping sobre yahoo-francia (aunque lo verifiqué con muchos otros sitios).
——————————————————————-
#!/bin/sh
A=ping4br.dat
B=ping4jp.dat
C=ping4fr.dat
cat /dev/null >$A
cat /dev/null >$B
cat /dev/null >$C
for i in `seq 4096`
do
#date >> $A
ping -c2 www.yahoo.com.br >>$A
ping -c2 www.yahoo.co.jp >>$B
ping -c2 www.yahoo.fr >> $C
sleep 1m
done
——————————————————————————-
Luego por medio del siguiente comando hayaba la información útil:
cat ping4fr.dat |grep «^rtt»|awk ‘BEGIN{FS=»/»}{print $5}’ >q4fr
La cual era una serie temporal donde la variable aleatoria era el intervalo de respuesta o sparseness time interval en inglés. Por supuesto tuve que verificar que dicha serie de tiempos fuese estacionaria, es decir que existía una única medida invariante de la probabilidad. Lo mas curioso es que no reproduje en ninguno de mis ensayos los resultados de Abe, sino que por el contrario me dio otro tipo de función.
Loxodromas, cuando el rumbo es constante.

Sobre una superficie esférica se llama loxodroma a las curvas que cortan a los meridianos bajo un ángulo constante. Dicho de otro modo, son trayectorias a lo largo de las cuales no cambia la posición de las agujas de una brújula. Son las trayectorias más simples de seguir por aviones y barcos, por que su uso en la navación se remonta a tiempos modernos. Para explicar esto, haré uso del lenguaje latex muy usado en la escritura de textos científicos. Sea lambda y teta a la longitud y latitud de un punto de la tierra respecto del meridiano cero y el ecuador, respectivamente. Denotemos por alpha el ángulo constante que forma la loxodroma con los meridianos, y sea lambda_0 la longitud del punto de corte de la loxodroma con el ecuador. Entonces cada loxodroma está determinada por los valores alpha y lambda_0. Sea h(teta) la función:
h(teta)=ln(sec(teta)+tg(teta)).
Luego si teta in [-pi/2, pi/2] la ecuación de la loxodroma es:
lambda=f(teta)+lambda_0.
donde f(teta)=tg(alpha) h(teta). Esta es la ecuación buscada en coordenadas geográficas. Si R es el radio de la Tierra entonces la ecuación paramétrica de la curva es:
x=R cos(teta) cos(f(teta))
y=R cos(teta) sen(f(teta))
z=R sen9teta)
En general, existen infinitas curvas loxodrómicas que unen dos puntos P y Q en una superficie esférica, pero solo una de ellas es la más corta. Las loxodromas se representan por lineas rectas en los mapas de Mercator de la Tierra.

De Solvay a La Falda


El famoso químico-físico Walter Nernst (1864 – 1941) logró que el industrial belga Ernest Solvay (1838 – 1922) patrocinara un congreso, que fue el primero de los famosos Congresos Solvay que se han efectuado desde 1911 en Bruselas, Bélgica (foto inferior). Este congreso resultó muy importante en la historia de la Física. En Abril de 2007 (foto superior) se realizó el primer Simposio de Mecánica Estadística, Teoría de la Información y Biofísica. Pero a diferencia del congreso de solvay, este fue pagado por el estado. Y no definió el paradigma actual de la física. Pero me pude enterar para donde va la moda. Actualmente se trata de unificar las fuerzas con la teoría de la información y la medida de Fisher. Por otro lado estos congresos siempre me permiten tomar contacto con las nuevas ideas de la física, y lo mejor en castellano.

Razonamiento Bayesiano vs Frecuentista.

La ciencia siendo una actividad humana, no es inmune a las modas y cambios de paradigmas. Las ideas bayesianas de inferencia con conocimiento de probabilidad a priori han vuelto a estar de moda en los investigadores tanto del mundo de la informática como en el mundo de la física. La clave del éxito del razonamiento bayesiano es no tener una muestra grande ni insesgada sino una apropiada asunción previa, como es formulada por los psicólogos cognitivos. La asunción previa es una hipótesis sobre como es la distribución de probabilidades (ddp) de un ensayo. Con la correcta ddp a priori, incluso con pocos datos, se puede hacer predicciones bayesianas con sentido. Por el contrario, una visión frecuentista hace menos asunciones a priori sobre la ddp. Lo que le da al método frecuentista una una robustez mayor respecto al bayesiano, pero es inpráctico a la hora de tomar decisiones en base a información limitada o incompleta, algo que los investigadores conviven todo el tiempo. Es decir una manera frecuentista de hacer las cosas reduciría el riesgo de prejuicio en la toma de decisiones, pero para el momento que se posea suficientes datos para sacar una conclusión el científico habrá muerto.
Inferencia Frecuentista:
En este caso se basa en la inferencia de hipótesis. Si se supone tener dos hipótesis H_0 y H_1. Donde H_0 se lo llama hipótesis nula, es decir que dentro de mi intervalo de confianza acepto que no hay diferencia entre el evento y el el de referencia. Y H_1 es la hipótesis alternativa, donde asumo que mi evento está fuera del intervalo de confianza. A esto se lo conoce como contraste de hipótesis. Donde puede ocurrir dos tipos de errores.
- Falso negativo: O error de tipo I, es cuando se rechaza una hipótesis nula cuando debería aceptarse.
- Falso positivo: O error de tipo II, es cuando se acepta una hipótesis alternativa cuando debería rechazarse.
Para el caso de muestras pequeñas se usa la t-students para estimar el intervalo de confianza. Es una forma de frecuencista de subsanar la falta de información en un muestreo aleatorio.
Inferencia Bayesiana:
El teorema de Bayes o de causa expresa que dado un suceso A de referencia y otro suceso B de estudio, entonces si es conocida las probabilidades P(B/A), P(A), P(B); entonces:
P(A/B)=(P(B/A)*P(A))/P(B)
Es decir habiendo ocurrido el suceso B cual es la probabilidad que sea causado por el suceso A. En general se llama a P(A) la ddp a priori, a P(B/A) la verosimilitud y a P(B) denominador de Bayes. En la practica P(B) no es fácil de hallar por eso se obtiene una probabilidad de causa aproximada.