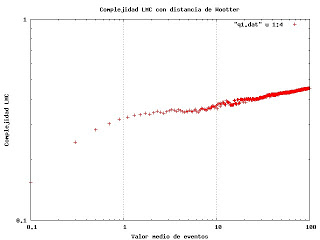
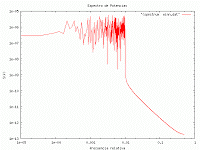
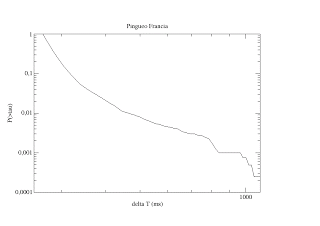
Un sistema complejo es un sistema compuesto por varias partes interconectadas o entrelazadas cuyos vínculos contienen información adicional y oculta al observador. Como resultado de las interacciones entre elementos, surgen propiedades nuevas que no pueden explicarse a partir de las propiedades de los elementos aislados. Dichas propiedades se denominan propiedades emergentes.
El sistema complicado, en contraposición, también está formado por varias partes pero los enlaces entre éstas no añaden información adicional. Nos basta con saber como funciona cada una de ellas para entender el sistema. En un sistema complejo, en cambio, existen variables ocultas cuyo desconocimiento nos impide analizar el sistema con precisión. Así pues, un sistema complejo, posee más información que la que da cada parte independientemente. Para describir un sistema complejo hace falta no solo conocer el funcionamiento de las partes sino conocer como se relacionan entre sí.Que características tiene un sistema complejo:
- El todo es más que la suma de las partes: esta es la llamada concepción holística. Como ya se ha dicho, la información contenida en el sistema en conjunto es superior a la suma de la información de cada parte analizada individualmente.
- Comportamiento difícilmente predecible: Debido a la enorme complejidad de estos sistemas la propiedad fundamental que los caracteriza es que poseen un comportamiento impredecible. Sólo somos capaces de prever su evolución futura hasta ciertos límites, siempre suponiendo un margen de error muy creciente con el tiempo. Para realizar predicciones más o menos precisas de un sistema complejo frecuentemente se han de usar métodos matemáticos como la estadística, la probabilidad o las aproximaciones numéricas como los números aleatorios.
- Son sistemas fuera del equilibrio: ello implica que tal sistema no puede automantenerse si no recibe un aporte constante de energía.
- Autoorganización: Todo sistema complejo emerge a partir de sus partes y fluctua hasta quedar fuertemente estabilizado en un atractor. Esto lo logra con la aparición de toda una serie de retroalimentaciones (o realimentaciones) positivas y negativas que atenúan cualquier modificación provocada por un accidente externo. Se puede afirmar que el sistema reacciona ante agresiones externas que pretendan modificar su estructura. Tal capacidad sólo es posible mantenerla sin ayuda externa mediante un aporte constante de energía.
- Las interrelaciones están regidas por ecuaciones no-lineales: estas no dan como resultado vectores ni pueden superponerse unas con otras. Normalmente todas ellas pueden expresarse como una superposición de muchas ecuaciones lineales. Pero ahí reside justamente el problema. Solo se pueden tratar de forma aproximada cosa que lleva a la imposibilidad de predicción antes citada. Por otra parte tales ecuaciones suelen tener una fuerte dependencia con las condiciones iniciales del sistema lo que hace aún más difícil, si cabe, evaluar su comportamiento.
- Es un sistema abierto y disipativo: energía y materia fluyen a través suyo. Pues justamente un sistema complejo, en gran medida se puede considerar como una máquina de generar orden para lo cual necesita del aporte energético constante que ya hemos comentado.
- Es un sistema adaptativo: como ya se ha dicho antes el sistema autoorganizado es capaz de reaccionar a estímulos externos respondiendo así ante cualquier situación que amenace su estabilidad como sistema. Experimenta así, fluctuaciones. Esto tiene un límite, naturalmente. Se dice que el sistema se acomoda en un estado y que cuando es apartado de él tiende a hacer todos los esfuerzos posibles para regresar a la situación acomodada. Esto ocurre por ejemplo con el cuerpo humano que lucha constantemente para mantener una misma temperatura corporal, o las estrellas cuya estructura se acomoda para mantener siempre una luminosidad casi constante.