
En la psicología y la sociología, una Trust Metric (Métrica de Confianza) es una medida sobre la confianza que se tiene de un miembro de un grupo por parte de otros que lo conocen. Las Trust Metric pueden ser abstraidas de manera tal que puedan ser implementadas en computadoras. Esto lo hace de interés para el estudio y ingeniería de comunidades virtuales, como Friendster y LiveJournal. El Ataque resistencia (Resistance Attack) es una propiedad importante de las métricas de confianza que reflejan su capacidad de no ser demasiado influenciadas por los agentes que tratan de manipular la confianza y participan de mala fe (es decir, que tienen como objetivo la presunción de abuso de confianza).
Las primeras formas de Trust Metric en fueron usadas en sistemas de comercio electrónico como eBay ‘s la cual es una puntuación por votos cliente-vendedor. Slashdot introdujo su concepto de karma, obtenidos de las actividades para promover la eficacia del grupo, este enfoque es muy influyente en comunidades virtuales para evaluar la confianza entre miembros.
El recurso de desarrollo para software libre Advogato se basa en un nuevo enfoque de los ataques resistentes utilizando la Trust Metric Raph Levien. Levien observó que el algoritmo PageRank (usado por Google) puede ser entendido como una Trust Metric con ataque resistente.
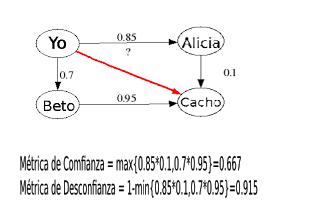
En la figura se muestra un algoritmo de Trust Metric y su aplicación práctica, supongamos que en mi red de infuencia están Alicia (métrica de confianza=0,85) y Beto (metrica de confianza = 0,7). Y desearía saber de antemano poder hacer un negocio con Cacho (que no lo conosco), ahora bien Cacho está en la red de confianza de Alicia (0,1) y Beto (0,95). Entonces una métrica de confianza sería
Las primeras formas de Trust Metric en fueron usadas en sistemas de comercio electrónico como eBay ‘s la cual es una puntuación por votos cliente-vendedor. Slashdot introdujo su concepto de karma, obtenidos de las actividades para promover la eficacia del grupo, este enfoque es muy influyente en comunidades virtuales para evaluar la confianza entre miembros.
El recurso de desarrollo para software libre Advogato se basa en un nuevo enfoque de los ataques resistentes utilizando la Trust Metric Raph Levien. Levien observó que el algoritmo PageRank (usado por Google) puede ser entendido como una Trust Metric con ataque resistente.
En la figura se muestra un algoritmo de Trust Metric y su aplicación práctica, supongamos que en mi red de infuencia están Alicia (métrica de confianza=0,85) y Beto (metrica de confianza = 0,7). Y desearía saber de antemano poder hacer un negocio con Cacho (que no lo conosco), ahora bien Cacho está en la red de confianza de Alicia (0,1) y Beto (0,95). Entonces una métrica de confianza sería
MC=max{0,85*0,1;0,7*0,95}=0,665
y una métrica de desconfianza sería
MD=1-min{0,85*0,1;0,7*0,95}=0, 915
Como MD > MC puedo tomar la decisión de no hacer negocios con él. Por supesto puedo extender la decisión al terreno de la lógica difusa compensatoria (ver post anteriores) pero ese no es el tema de este post.